Text-Conditioned Encoder
A pretrained image-language encoder processes the image and target query, then produces target-conditioned visual representations. These features tell the counting branches what object concept should be counted.
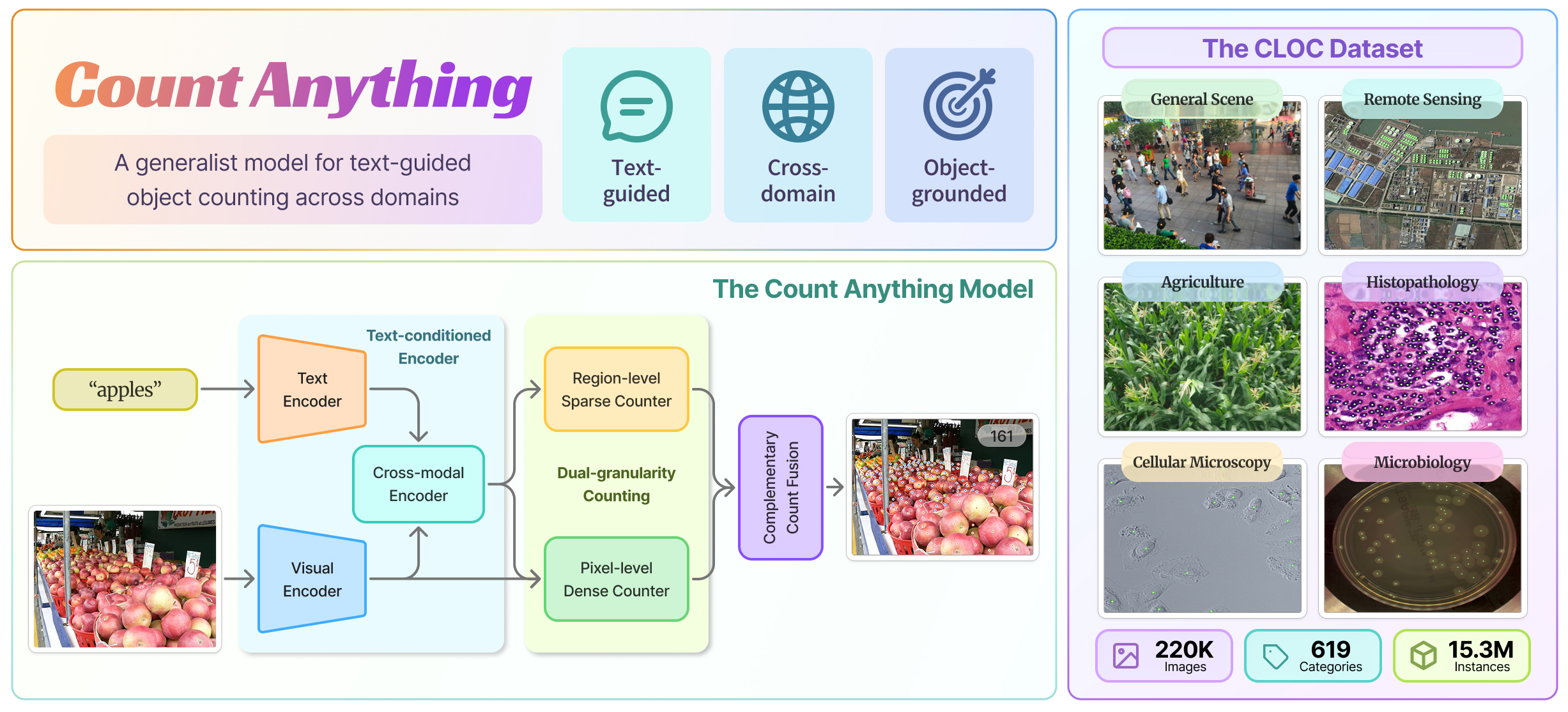
A generalist model for text-guided object counting across domains.
Count Anything turns an image and a text query into a set of localized instance points. The point set gives both the count and the spatial evidence behind it.
Overview
Object counting remains largely fragmented across domain-specific datasets and task formulations, despite the rapid progress of generalist vision models. Existing counting models are often tailored to particular scenarios, such as crowds, vehicles, cells, crops, or remote-sensing objects, and therefore struggle to generalize across categories, visual domains, object scales, and density distributions. In this paper, we study text-guided object counting across domains, where a model takes an image and a natural-language query as input and returns an instance-grounded set of target points whose cardinality gives the count. This formulation unifies category-conditioned counting with interpretable spatial localization.
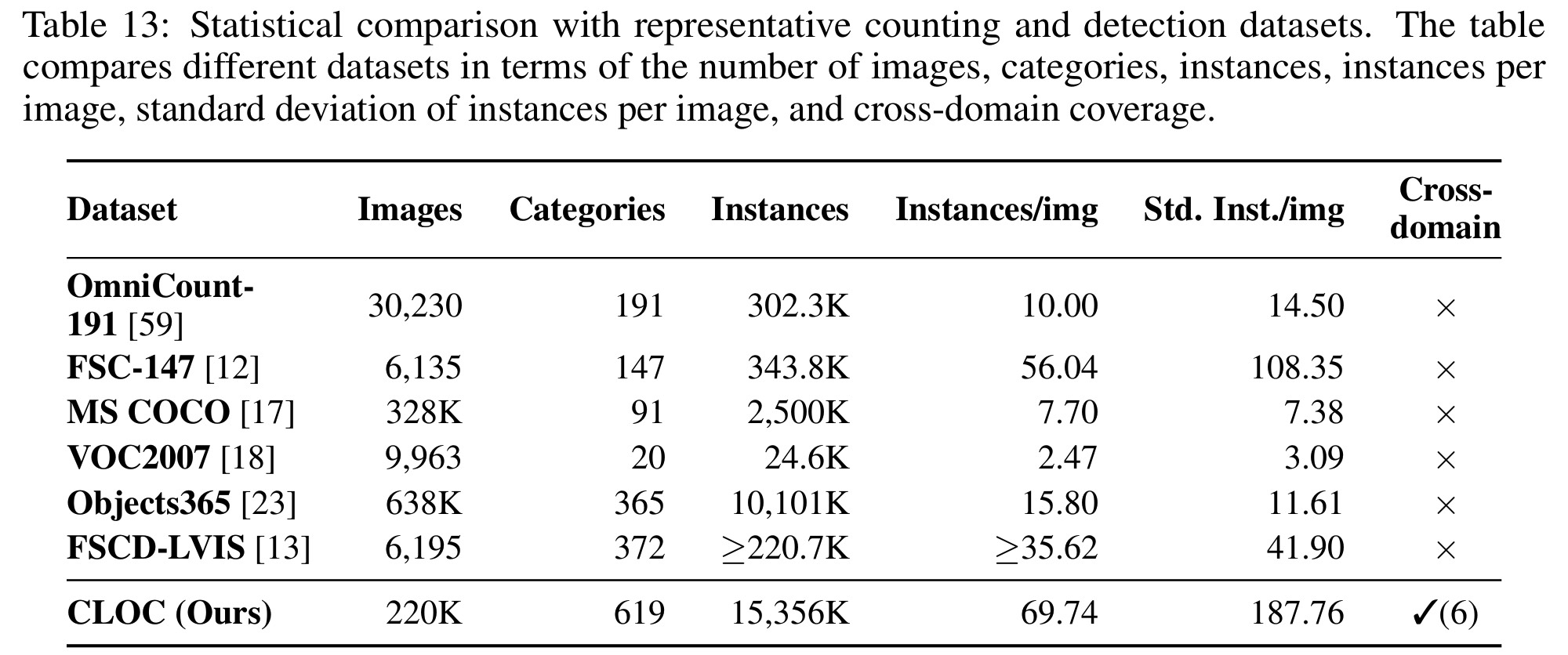
To support this setting, we construct CLOC, a Cross-domain Large-scale Object Counting dataset that reorganizes diverse public data sources into a unified counting benchmark. CLOC covers six visual domains, including General Scene, Remote Sensing, Histopathology, Cellular Microscopy, Agriculture, and Microbiology, and contains about 220K images, 619 categories, and 15M object instances. Based on CLOC, we further propose Count Anything, a generalist model for text-guided object counting.
Instead of using density maps as the final output, which is most widely used in current counting models, our Count Anything adopts discrete instance points and performs dual-granularity instance enumeration. A Region-level Sparse Counter provides object-level anchoring for large and sparse targets, while a Pixel-level Dense Counter captures small, crowded, and weakly bounded targets through dense point prediction. A point-centric supervision strategy enables learning from heterogeneous annotations, and Complementary Count Fusion combines both counters in a parameter-free manner. Extensive experiments show that Count Anything achieves strong counting accuracy and multi-domain generalization, substantially outperforming existing open-world counting methods.
Interactive Demo
Choose a sample image or upload your own, then Count Anything will return instance-grounded counting points.
The result will appear here with Fused, RSC, and PDC views.
If the sample demo does not respond, open the Hugging Face Space directly.
Pipeline
Count Anything predicts a point set by combining text-conditioned visual understanding with complementary region-level and pixel-level counting.
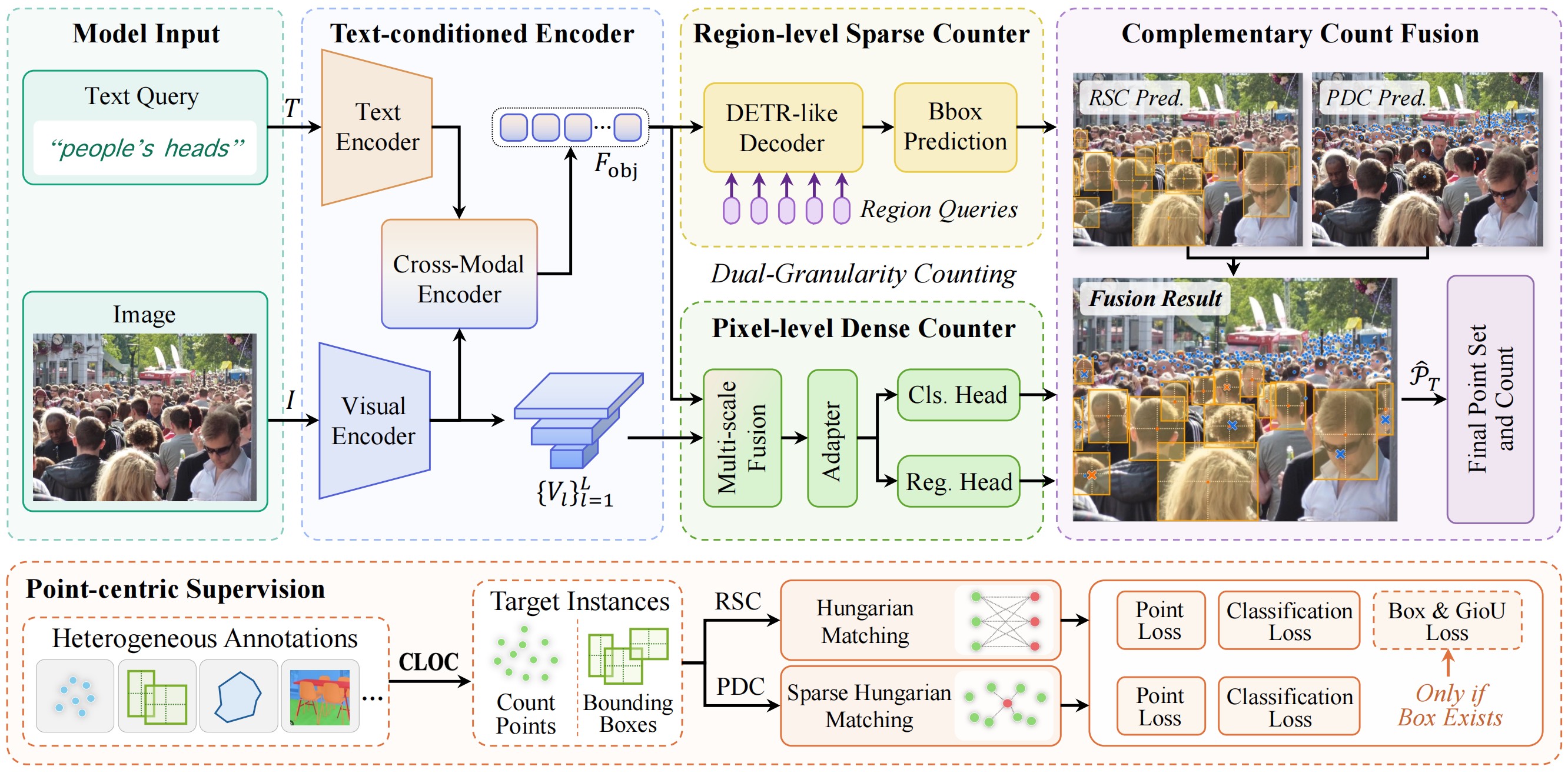
A pretrained image-language encoder processes the image and target query, then produces target-conditioned visual representations. These features tell the counting branches what object concept should be counted.
The Region-level Sparse Counter provides object-level anchors for large, sparse, and clearly bounded targets, while the Pixel-level Dense Counter enumerates small, crowded, or weakly bounded targets with dense point prediction.
RSC and PDC predictions are fused with a lightweight, parameter-free rule. The fusion suppresses duplicate predictions for the same target while preserving dense complementary points in crowded regions.
All valid instances are supervised through counting points, while reliable boxes are used only when they exist. This allows Count Anything to learn from heterogeneous annotations.
CLOC Dataset
CLOC is a cross-domain benchmark for text-guided object counting at scale.
CLOC reorganizes diverse public data sources into a unified category-specified counting format. In CLOC, category names serve as textual queries: given an image and a query, the model must count all visible instances corresponding to the queried target.
The dataset covers six visual domains and preserves broad variations in category space, object scale, target density, and imaging conditions. It provides a unified training and evaluation foundation for generalist counting models.

Because some source datasets used by CLOC are subject to license and redistribution restrictions, we cannot directly release the complete CLOC image set. We release the CLOC annotation files produced by our re-annotation process and the subset of augmented images that can be redistributed. To reproduce the complete CLOC dataset, please download the original source images and follow the preprocessing, rebuilding, and audit steps in the data preparation guide.
A processed, ready-to-use copy of the complete CLOC dataset is available upon request. Please contact us by email for access.
Main Results
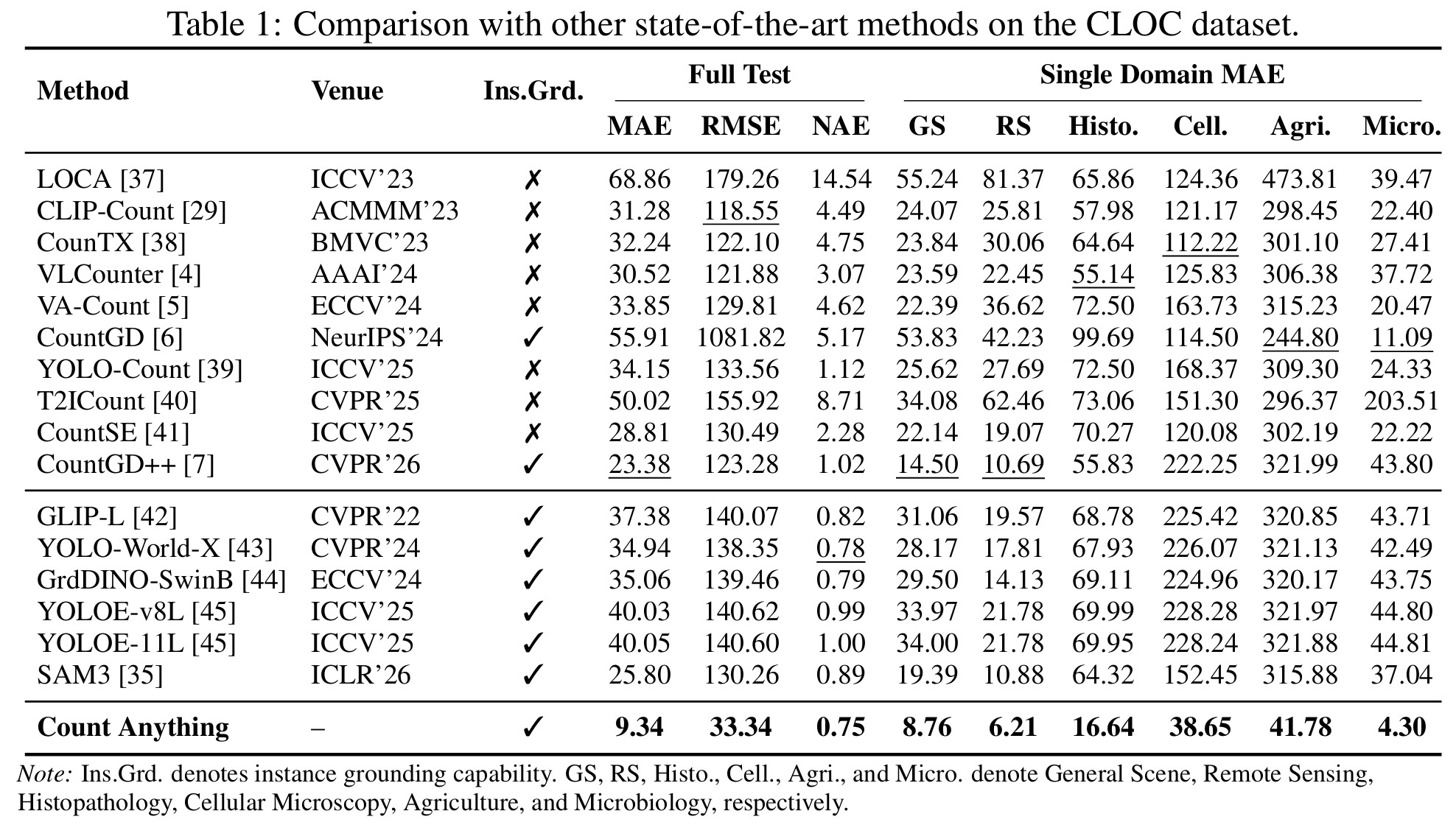
Count Anything achieves strong cross-domain counting accuracy on the CLOC test split.
On the full CLOC test set, Count Anything achieves 9.34 MAE, 33.34 RMSE, and 0.75 NAE, outperforming representative open-world counting methods as well as detection and segmentation foundation models evaluated with their released checkpoints and standard inference pipelines.
Across the six single-domain splits, Count Anything obtains the best MAE among compared methods: 8.76 on General Scene, 6.21 on Remote Sensing, 16.64 on Histopathology, 38.65 on Cellular Microscopy, 41.78 on Agriculture, and 4.30 on Microbiology.
Visualizations
Qualitative comparisons show how Count Anything localizes target instances across domains with very different object scales and density patterns.
Select a domain to inspect prediction examples. Each visualization compares Count Anything with ground truth and representative baseline methods on CLOC test samples.

Resources
Find the paper, code, model checkpoint, demo, dataset guide, and contact information for Count Anything.
Training, evaluation, inference, and data preparation code for Count Anything.
Open RepositoryReleased Count Anything checkpoint for inference, validation, and test-only reproduction.
Open ModelInteractive browser demo for uploading an image and entering a text query.
Open DemoPreprint page for Count Anything.
Open arXivInstructions for preparing the complete CLOC dataset from released annotations, distributable augmented images, and source datasets.
View GuideFor dataset access requests and project questions.
Email UsCitation
If you find Count Anything useful in your research, please consider citing our paper.
@article{lei2026count_anything,
title={Count Anything},
author={Lei, Mengqi and Cheng, Shuokun and Bao, Wei and Du, Shaoyi and Yong, Jun-Hai and Li, Siqi and Gao, Yue},
journal={arXiv preprint arXiv:2605.30846},
year={2026}
}